
For Syra (USA) - Multi-Agentic Framework
MAIN-RAG enhances Retrieval-Augmented Generation (RAG) systems by addressing issues related to noisy or irrelevant retrieved documents that reduce performance and reliability.
![]() Professional Technology & Gen AI Solution Company
Based On World
Professional Technology & Gen AI Solution Company
Based On World
Make a Call
+1 (415) 630-2010
MAIN-RAG enhances Retrieval-Augmented Generation (RAG) systems by addressing issues related to noisy or irrelevant retrieved documents that reduce performance and reliability.
֍ Training-Free: No additional training data or fine-tuning required.
֍ Collaborative Multi-Agent Approach: Leverages multiple LLM agents to filter and score retrieved documents collaboratively.
֍ Adaptive Filtering: Dynamically adjusts the relevance threshold based on score distribution, reducing noise while maintaining high recall of relevant documents.
֍ Inter-Agent Consensus: Ensures robust document selection through agent agreement.
֍ Text Embedding: Using advanced NLP techniques, the textual data is transformed into
embeddings, numerical representations capturing the semantic meaning of the
content.
֍ Model Training: Pre-trained language models, such as GPT-3.5, are fine-tuned to
understand the specific language and context of resumes and job descriptions.
֍ Performance: Improved answer accuracy by 2-11% across four QA benchmarks compared to traditional RAG systems.
֍ Efficiency: Reduces irrelevant documents, decreasing computational overhead.
֍ Consistency: Provides more reliable and consistent responses.
֍ Offers an effective, competitive, and training-free alternative to training-based RAG solutions.
֍ Structure the context as indents paired with corresponding responses.
֍ Parse the context into small chunks based on indents and responses. ֍ Each chunk includes an indent and response, ensuring easy retrieval in a vector database.Vector DB (e.g., Qdrant):
֍ Efficient indexing and searching for more accurate query results.
֍ Enables faster retrieval of high-dimensional, unstructured data.
֍ Handles large datasets with billions of data points.
֍ Combines dense and sparse retrieval methods to enhance search precision.
֍ Effective for domain-specific vocabulary, such as healthcare data.
֍ Executes hybrid search leveraging semantic understanding and keyword matching.
֍ Dense Embeddings: Use models like OpenAI's embeddings to capture text's semantic meaning.
֍ Sparse Embeddings: Employ methods like BM25 for keyword frequency and relevance.
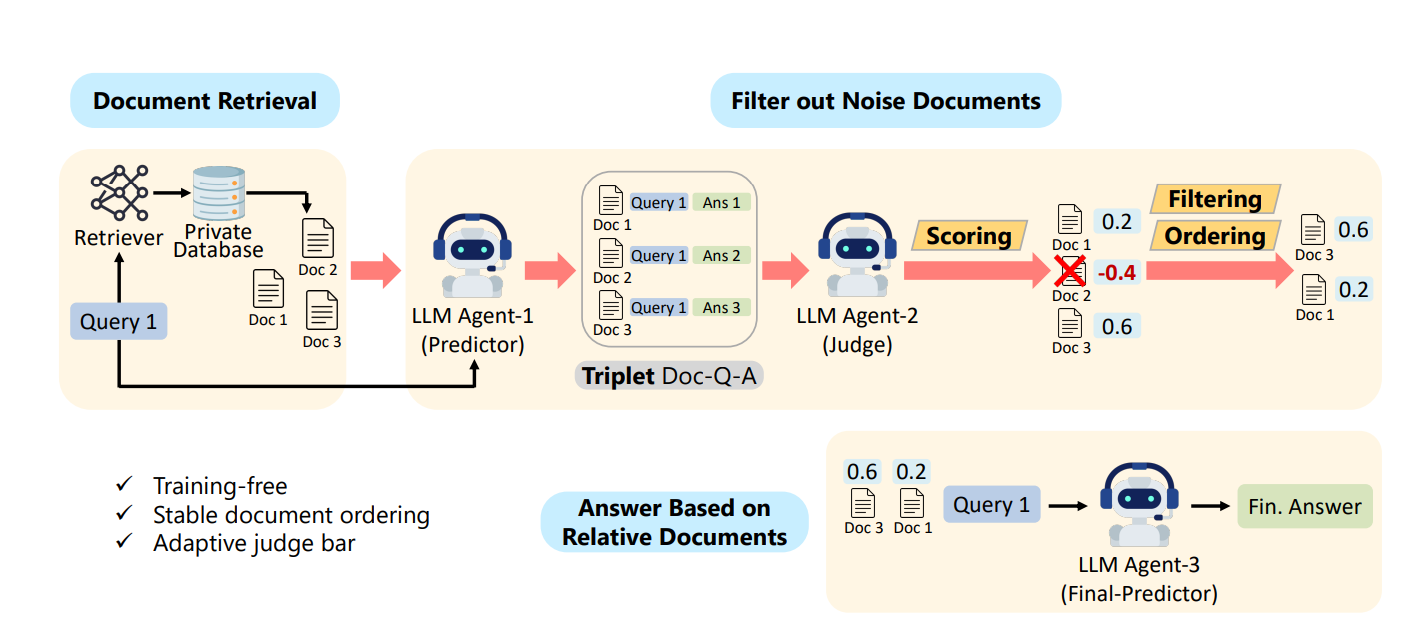
Agent-1 (Predictor)
֍ Analyzes retrieved document chunks and attempts to answer the query.
֍ Produces Document-Query-Answer (Doc-Q-A) triplets for further evaluation.
֍ Rephrases the query if returned chunks lack relevance.
Agent-2 (Judge)
֍ Evaluates Doc-Q-A triplets to assess relevance.
֍ Assigns "Yes" or "No" to each triplet:
"Yes" for relevant documents supporting the query and answer.
"No" for irrelevant or unhelpful documents.
֍ Quantifies judgments into relevance scores for filtering and ordering.
Agent-3 (Final-Predictor):
֍ Processes the refined list of relevant documents from Agent-2.
֍ Generates the final query response by extracting information from the cleaned document set.
Ready to take your business to the next level with our implementation? Contact us today to learn more about our services and how we can help you optimize your business operations for success.
Call NowTake the first step towards transforming your business with generative AI. Contact us today to schedule a consultation with one of our AI specialists. Together, we’ll discuss your objectives and explore how our cutting-edge generative AI solutions can drive innovation and success for your business.
Copyright @2024 Adople AI.All Rights Reserved