
For AMGEN.
Founded in 1980, Amgen has grown to be one of the world's leading independent biotechnology Companies.
![]() Professional Technology & Gen AI Solution
Company
Based On World
Professional Technology & Gen AI Solution
Company
Based On World
Make a Call
+1 (415) 630-2010
Founded in 1980, Amgen has grown to be one of the world's leading independent biotechnology Companies.
֍ We can extract the code from the repo link like github or
directory which
contains the code base.
֍ This directory loader will load the entire directory to extract the code.
֍ This will be the easiest way to extract the code because it comes up with the
metadata of the code file.
֍ langchain_unstructured library will be used for extracting the code
from the
files.
֍ llama_index.core.node_parser.CodeSplitter
֍ Split code using an AST(Abstract Syntax Tree) parser.
֍ We can define the programming language of the code using language
parameter
֍ chunk_lines: The number of lines to include in each chunk.
֍ chunk_lines_overlap: How many lines of code each chunk overlaps with.
֍ max_chars: Maximum number of characters per chunk.
Sample Code
from llama_index.core.node_parser import CodeSplitter
splitter = CodeSplitter(
language="python",
chunk_lines=40, #lines per chunk
chunk_lines_overlap=15, #lines overlap between chunks
max_chars=1500, #max chars per chunk
)
nodes = splitter.get_nodes_from_documents(documents)
Model name: jinaai/jina-embeddings-v2-base-code
֍ Specialized embeddings for code-to-code similarity search. We’ll use the
jinaai/jina-embeddings-v2-base-code model for the task.
֍ It supports English and 30 widely used programming languages with an 8192
sequence length. Let’s call this code model
֍ We can use the Qdrant vector db to store the chunk of code. It provides more
accurate results.
֍ Advantage of their efficient indexing and searching techniques, vector
databases enable faster and more accurate retrieval of unstructured data
already represented as vectors, which can help put in front of users the most
relevant results to their queries.
֍ Efficient storage and indexing of high-dimensional data.
֍ Ability to handle large-scale datasets with billions of data points.
֍ Ability to handle vectors derived from complex data types like code and
natural language.
Hybrid Search:
Hybrid search in Qdrant combines dense and sparse retrieval methods to
enhance search precision by leveraging both semantic understanding and
keyword matching. This approach is particularly effective in scenarios where
domain-specific vocabulary is prevalent, such as in healthcare or legal
contexts
Ingestion Stage:
1. Dense Embeddings: Generate dense embeddings for each document using
models like OpenAI's embeddings, which capture the semantic meaning of
the text.
2. Sparse Embeddings: Create sparse embeddings using traditional keyword-based methods, such as BM25, which focus on keyword frequency and relevance.
Retrieval Stage:
1. User's Query: Convert the user's query into multiple embeddings to capture both semantic meaning and specific keywords.
2. Hybrid Search: Execute a hybrid search that utilizes both dense and sparse embeddings to retrieve relevant documents.
3. Reranking: Apply late interaction embeddings to the retrieved documents to rerank them, ensuring the results closely align with the user's intent.
Deepseek:
֍ open-source Mixture-of-Experts (MoE) code language model that achieves
performance comparable to GPT4-Turbo in code-specific tasks.
֍ DeepSeek-Coder-V2 is further pre-trained from an intermediate checkpoint of
DeepSeek-V2 with additional 6 trillion tokens.
֍ DeepSeek-Coder-V2 demonstrates significant advancements in various
aspects of code-related tasks, as well as reasoning and general capabilities.
Additionally, DeepSeek-Coder-V2 expands its support for programming
languages from 86 to 338, while extending the context length from 16K to
128K.
֍ DeepSeek-Coder-V2 achieves superior performance compared to
closed-source models such as GPT4-Turbo, Claude 3 Opus, and Gemini 1.5
Pro in coding and math benchmarks.
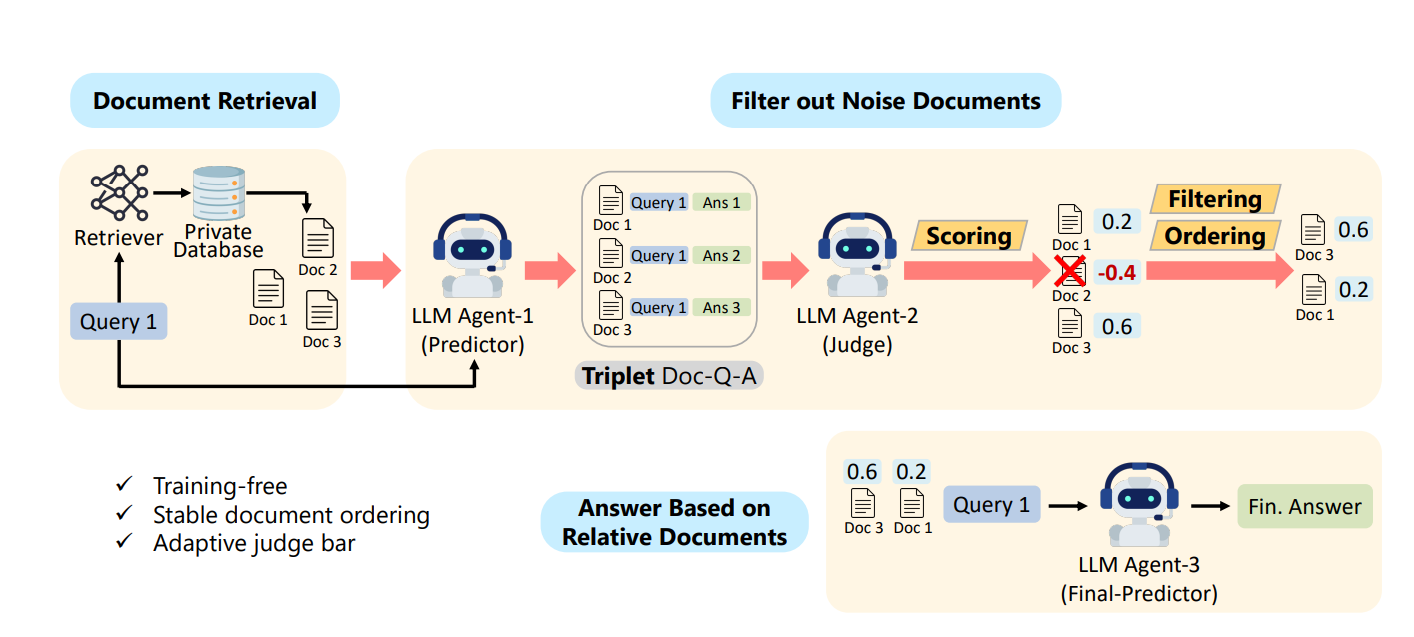
֍ Multi Agent FIltering Retrieval-Augmented Generation (MAIN-RAG),
a
novel training-free framework designed to enhance the performance and
reliability of RAG systems.
֍ This consensus-driven strategy ensures that only the most relevant and
high-quality code chunks are utilized for generation, significantly reducing
noise without sacrificing recall.
1. Agent-1 (Retriever): Query Processing and Code Retrieval
֍ Prompt Enhancer:
this agent enhances prompt using LLM to retrieve the
relevant code chunks from vector DB.
֍ Retrieve Relevant Code Chunks:Upon receiving a code generation query,
convert it into an embedding and perform a similarity search against the
vector database to fetch pertinent code snippets.
2. Agent-2 (Evaluator): Code Evaluation and Ranking
֍ Assess Relevance and Quality: Employ a language model to evaluate the
retrieved code snippets, determining their relevance and quality concerning
the query.
֍ Filter and Rank: Discard non-relevant or low-quality snippets and rank the
remaining ones based on their relevance scores.
3. Agent-3 (Synthesizer): Code Synthesis
֍ Combines retrieved code snippets based on query requirements, resolving
dependencies and conflicts.
֍ Supports user feedback for enhancing and finalizing the synthesized code.
֍ Generates modular, optimized code with clear comments and usage
instructions.
Ready to take your business to the next level with our implementation? Contact us today to learn more about our services and how we can help you optimize your business operations for success.
Call NowTake the first step towards transforming your business with generative AI. Contact us today to schedule a consultation with one of our AI specialists. Together, we’ll discuss your objectives and explore how our cutting-edge generative AI solutions can drive innovation and success for your business.
Copyright @2024 Adople AI.All Rights Reserved